The central quantity in Bayesian inference, the posterior, can usually not be calculated analytically, but needs to be estimated by numerical integration, which is typically done with a Monte-Carlo algorithm. The three main algorithm classes for doing so are
- Rejection sampling
- Markov-Chain Monte Carlo (MCMC) sampling
- Sequential Monte Carlo (SMC) sampling
I have previously given an introduction to MCMC sampling, which is currently probably the most common of the three methods. MCMC samplers are implemented in many of the popular software packages such as BUGS, JAGS or STAN. However, there are cases where it makes sense to fall back to the most basic sampler, the rejection sampler, which may be viewed as a primitive version of an SMC. If you have a prior distribution and a likelihood function, the rejection sampler works like this:
repeat
1. draw random value from the prior
2. calculate likelihood
3. accept value proportional to the likelihood
Because you accept proportional to your target, the distribution of accepted parameter values will approach the posterior.
There is one disadvantage of this method that is obvious – you propose from the whole parameter space, which means that you will typically get a lot of rejections, which is costly (well, it’s called rejection sampling after all). MCMC, in contrast, does a random walk (Markov-chain) in parameter space, and thereby concentrates sampling on the important parameter areas. That is why it is more efficient. But MCMC also has a drawback – because the next step depends on the last step, it’s difficult to parallelize. SMC and rejection sampling, on the other hand, work in parallel anyway and are therefore trivially parallelizable. To see the difference to other sampling methods visually, have a look at this illustration of the three methods, taken from our 2011 EL review
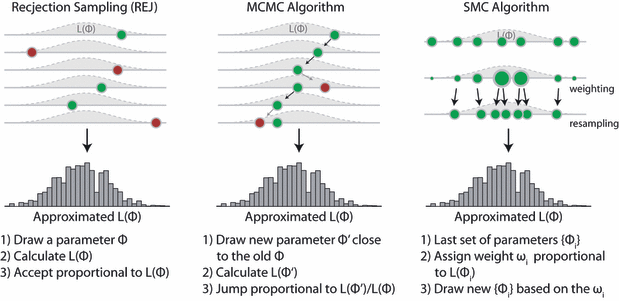
Illustration of the three main classes of Monte-Carlo samplers
There are more benefits to rejection sampling than parallelization. For example when using rejection sampling for Approximate Bayesian Computation, there is the subtle but practically relevant advantage that you don’t have to choose the acceptance parameter in advance of the simulations. Finally, rejection sampling is a modern classic. I hope that’s enough motivation.
So, here is how you would do it in R:
An example in R
Assume we want to draw from a beta distribution with shape parameters 3,6, which looks like this
curve(dbeta(x, 3,6),0,1)
Target distribution
To do this, we first create a data.frame with 100000 random values between 0 and 1, and calculate their beta density values
sampled <- data.frame(proposal = runif(100000,0,1))
sampled$targetDensity <- dbeta(sampled$proposal, 3,6)Now, accept proportional to the targetDensity. It’s easiest if we calculate the highest density value, and then accept the others in relation to that
maxDens = max(sampled$targetDensity, na.rm = T)
sampled$accepted = ifelse(runif(100000,0,1) < sampled$targetDensity / maxDens, TRUE, FALSE)Plot the result
hist(sampled$proposal[sampled$accepted], freq = F, col = "grey", breaks = 100)
curve(dbeta(x, 3,6),0,1, add =T, col = "red")
Sample created by rejection sampling, and comparison to the target distribution
A copy of the entire code is available on GitHub here
Related posts
The EasyABC package for Approximate Bayesian Computation in R


Pingback: Distilled News | Data Analytics & R
Nice post with nice plots. Thanks!
LikeLike
Nice post; thanks.
A small observation on the R code which will improve the efficiency. These steps could be simplified:
to
sampled <- data.frame(proposal = runif(100000, 0, 1)) sampled <- transform(sampled, targetDensity = dbeta(proposal, 3, 6)) sampled <- transform(sampled, accepted = runif(100000, 0, 1) < targetDensity / max(targetDensity, na.rm = TRUE))The main change (the other changes just suit my style and abhorrence of
$in code 🙂 is to ditch theifelse()and compute the logical vectoraccepteddirectly from the comparison operator<; theifelse()bit is making this run ~ an order magnitude slower (on my machine) than just computing the comparison directly (in fact your code does this, but adds theifelse()bit on top).I’m looking forward to the sequential MC post now.
LikeLike
Hi – thanks a lot for the code, this is definitely more elegant. I have considered changing it in the main post, but after a bit of thinking I decided to keep the old version because it seems to me that it’s easier to understand when you see this for the first time, despite being a bit clumsy.
About the SMC – I have an SMC example ready, I just didn’t have much time for this blog lately, so I didn’t manage to post it – if you want a peek it’s here https://github.com/florianhartig/LearningBayes/blob/master/CommentedCode/02-Samplers/SMC/SMC.md
LikeLiked by 1 person
Pingback: A simple explanation of rejection sampling in R — theoretical ecology – Encaion
Pingback: Bayes’ Theorem Primer – Connections